Offensive AI Compilation
A curated list of useful resources that cover Offensive AI.
📁 Contents 📁
- 🚫 Abuse 🚫
- 🔧 Use 🔧
- 📊 Surveys 📊
- 🗣 Contributors 🗣
- ©️ License ©️
🚫 Abuse 🚫
Exploiting the vulnerabilities of AI models.
🧠 Adversarial Machine Learning 🧠
Adversarial Machine Learning is responsible for assessing their weaknesses and providing countermeasures.
⚡ Attacks ⚡
It is organized into four types of attacks: extraction, inversion, poisoning and evasion.
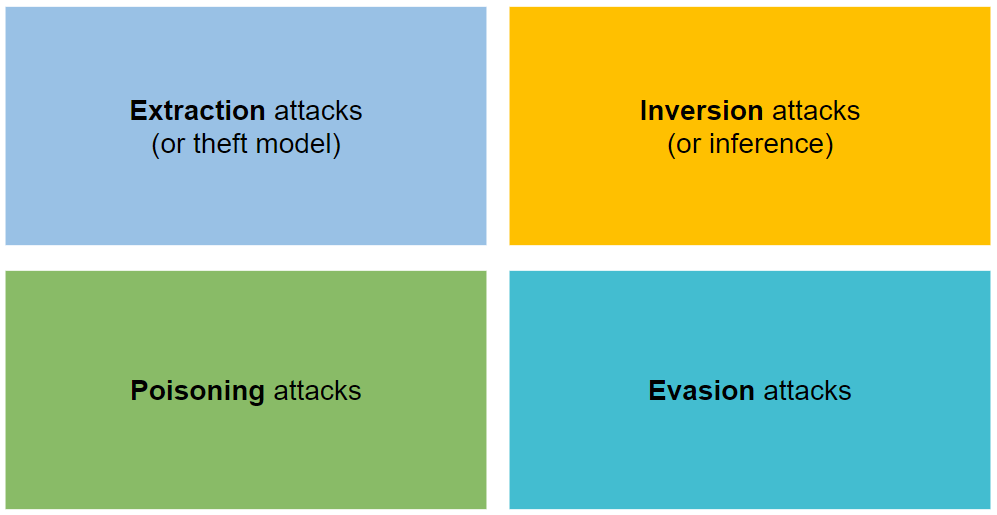
🔒 Extraction 🔒
It tries to steal the parameters and hyperparameters of a model by making requests that maximize the extraction of information.
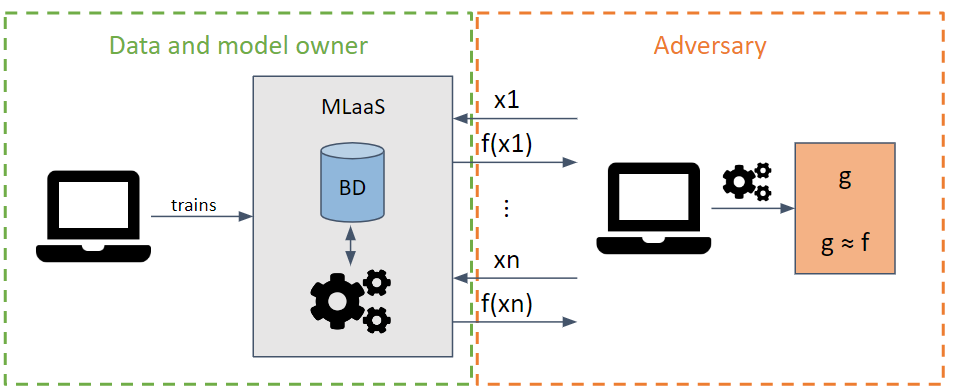
Depending on the knowledge of the adversary’s model, white-box and black-box attacks can be performed.
In the simplest white-box case (when the adversary has full knowledge of the model, e.g., a sigmoid function), one can create a system of linear equations that can be easily solved.
In the generic case, where there is insufficient knowledge of the model, the substitute model is used. This model is trained with the requests made to the original model in order to imitate the same functionality as the original one.
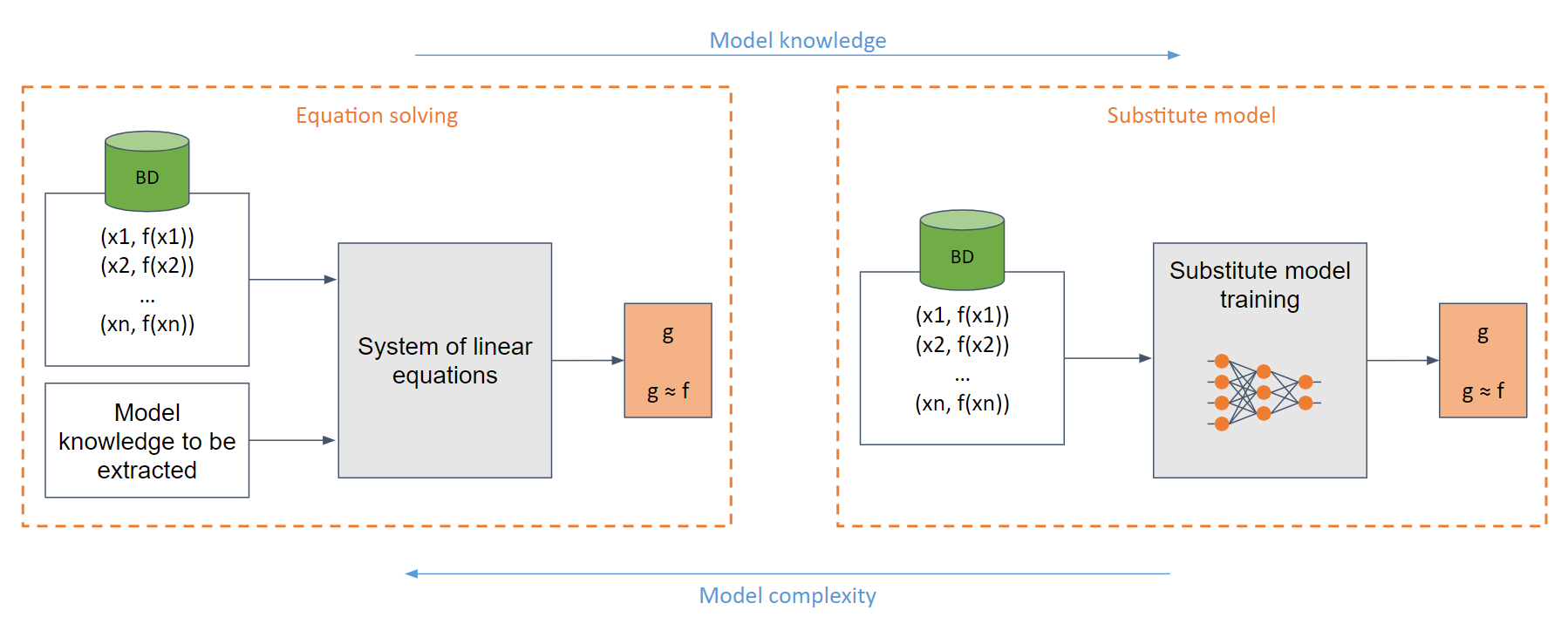
⚠️ Limitations ⚠️
-
Training a substitute model is equivalent (in many cases) to training a model from scratch.
-
Very computationally intensive.
-
The adversary has limitations on the number of requests before being detected.
🛡️ Defensive actions 🛡️
-
Rounding of output values.
-
Use of differential privacy.
-
Use of ensembles.
-
Use of specific defenses
🔗 Useful links 🔗
- Stealing Machine Learning Models via Prediction APIs
- Stealing Hyperparameters in Machine Learning
- Knockoff Nets: Stealing Functionality of Black-Box Models
- Model Extraction Warning in MLaaS Paradigm
- Copycat CNN: Stealing Knowledge by Persuading Confession with Random Non-Labeled Data
- Prediction Poisoning: Towards Defenses Against DNN Model Stealing Attacks
- Stealing Neural Networks via Timing Side Channels
- Model Stealing Attacks Against Inductive Graph Neural Networks
- High Accuracy and High Fidelity Extraction of Neural Networks
- Poisoning Web-Scale Training Datasets is Practical
- Polynomial Time Cryptanalytic Extraction of Neural Network Models
- Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models
- Awesome Data Poisoning And Backdoor Attacks: A curated list of papers & resources linked to data poisoning, backdoor attacks and defenses against them.
- BackdoorBox: An Open-sourced Python Toolbox for Backdoor Attacks and Defenses.
- Stealing Part of a Production Language Model
- Hard-Label Cryptanalytic Extraction of Neural Network Models
- https://www.anthropic.com/news/detecting-and-preventing-distillation-attacks
⬅️ Inversion (or inference) ⬅️
They are intended to reverse the information flow of a machine-learning model.
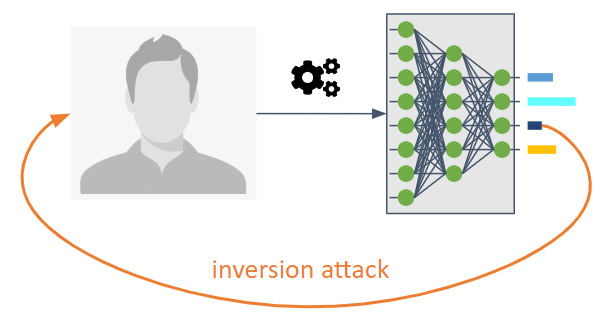
They enable an adversary to know the model that was not explicitly intended to be shared.
They allow us to know the training data or information as statistical properties of the model.
Three types are possible:
-
Membership Inference Attack (MIA): An adversary attempts to determine whether a sample was employed as part of the training.
-
Property Inference Attack (PIA): An adversary aims to extract statistical properties that were not explicitly encoded as features during the training phase.
-
Reconstruction: An adversary tries to reconstruct one or more samples from the training set and/or their corresponding labels. Also called inversion.
🛡️ Defensive actions 🛡️
-
Use of advanced cryptography. Countermeasures include differential privacy, homomorphic cryptography and secure multiparty computation.
-
Use of regularization techniques such as Dropout due to the relationship between overtraining and privacy.
-
Model compression has been proposed as a defense against reconstruction attacks.
🔗 Useful links 🔗
- Membership Inference Attacks Against Machine Learning Models
- Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures
- Machine Learning Models that Remember Too Much
- ML-Leaks: Model and Data Independent Membership Inference Attacks and Defenses on Machine Learning Models
- Deep Models Under the GAN: Information Leakage from Collaborative Deep Learning
- LOGAN: Membership Inference Attacks Against Generative Models
- Overfitting, robustness, and malicious algorithms: A study of potential causes of privacy risk in machine learning
- Comprehensive Privacy Analysis of Deep Learning: Stand-alone and Federated Learning under Passive and Active White-box Inference Attacks
- Inference Attacks Against Collaborative Learning
- The Secret Sharer: Evaluating and Testing Unintended Memorization in Neural Networks
- Towards the Science of Security and Privacy in Machine Learning
- MemGuard: Defending against Black-Box Membership Inference Attacks via Adversarial Examples
- Extracting Training Data from Large Language Models
- Property Inference Attacks on Fully Connected Neural Networks using Permutation Invariant Representations
- Extracting Training Data from Diffusion Models
- High-resolution image reconstruction with latent diffusion models from human brain activity
- Stealing and evading malware classifiers and antivirus at low false positive conditions
- Realistic fingerprint presentation attacks based on an adversarial approach
- Active Adversarial Tests: Increasing Confidence in Adversarial Robustness Evaluations.
- GPT Jailbreak Status: Updates on the status of jailbreaking the OpenAI GPT language model.
- Order of Magnitude Speedups for LLM Membership Inference
- What GPT-oss Leaks About OpenAI’s Training Data
- On the Detectability of Active Gradient Inversion Attacks in Federated Learning
- The Membership Inference Attack Bait-and-Switch
- How Your Credentials Are Leaked by LLM Agent Skills: An Empirical Study
- A Theory of Prompt Injection (and why you should study roles)
💉 Poisoning 💉
They aim to corrupt the training set by causing a machine-learning model to reduce its accuracy.
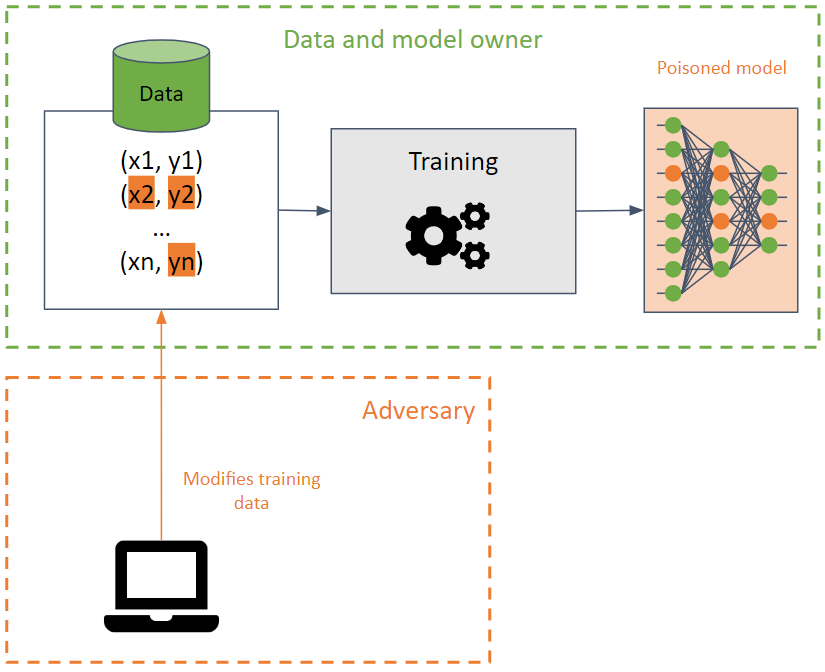
This attack is difficult to detect when performed on the training data since the attack can propagate among different models using the same training data.
The adversary seeks to destroy the availability of the model by modifying the decision boundary and, as a result, producing incorrect predictions or, create a backdoor in a model. In the latter, the model behaves correctly (returning the desired predictions) in most cases, except for certain inputs specially created by the adversary that produce undesired results. The adversary can manipulate the results of the predictions and launch future attacks.
🔓 Backdoors 🔓
BadNets are the simplest type of backdoor in a machine learning model. Moreover, BadNets are able to be preserved in a model, even if they are retrained again for a different task than the original model (transfer learning).
It is important to note that public pre-trained models may contain backdoors.
🛡️ Defensive actions 🛡️
-
Detection of poisoned data, along with the use of data sanitization.
-
Robust training methods.
-
Specific defenses.
- Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks
- STRIP: A Defence Against Trojan Attacks on Deep Neural Networks
- Detecting Backdoor Attacks on Deep Neural Networks by Activation Clustering
- ABS: Scanning Neural Networks for Back-doors by Artificial Brain Stimulation
- DeepInspect: A Black-box Trojan Detection and Mitigation Framework for Deep Neural Networks
- Defending Neural Backdoors via Generative Distribution Modeling
- A Comprehensive Survey on Backdoor Attacks and Their Defenses in Face Recognition Systems
- DataElixir: Purifying Poisoned Dataset to Mitigate Backdoor Attacks via Diffusion Models
🔗 Useful links 🔗
- Poisoning Attacks against Support Vector Machines
- Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning
- Trojaning Attack on Neural Networks
- Fine-Pruning: Defending Against Backdooring Attacks on Deep Neural Networks
- Poison Frogs! Targeted Clean-Label Poisoning Attacks on Neural Networks
- Spectral Signatures in Backdoor Attacks
- Latent Backdoor Attacks on Deep Neural Networks
- Regula Sub-rosa: Latent Backdoor Attacks on Deep Neural Networks
- Hidden Trigger Backdoor Attacks
- Transferable Clean-Label Poisoning Attacks on Deep Neural Nets
- TABOR: A Highly Accurate Approach to Inspecting and Restoring Trojan Backdoors in AI Systems
- Towards Poisoning of Deep Learning Algorithms with Back-gradient Optimization
- When Does Machine Learning FAIL? Generalized Transferability for Evasion and Poisoning Attacks
- Certified Defenses for Data Poisoning Attacks
- Input-Aware Dynamic Backdoor Attack
- How To Backdoor Federated Learning
- Planting Undetectable Backdoors in Machine Learning Models
- Fool the AI!: Hackers can use backdoors to poison training data and cause an AI model to misclassify images. Learn how IBM researchers can tell when data has been poisoned, and then guess what backdoors have been hidden in these datasets. Can you guess the backdoor?
- Backdoor Toolbox: A compact toolbox for backdoor attacks and defenses.
- LaserGuider: A Laser Based Physical Backdoor Attack against Deep Neural Networks
- Energy-latency attacks via sponge poisoning
- ShadowCoT: Cognitive Hijacking for Stealthy Reasoning Backdoors in LLMs
- A small number of samples can poison LLMs of any size
🏃♂️ Evasion 🏃♂️
An adversary adds a small perturbation (in the form of noise) to the input of a machine learning model to make it classify incorrectly (example adversary).
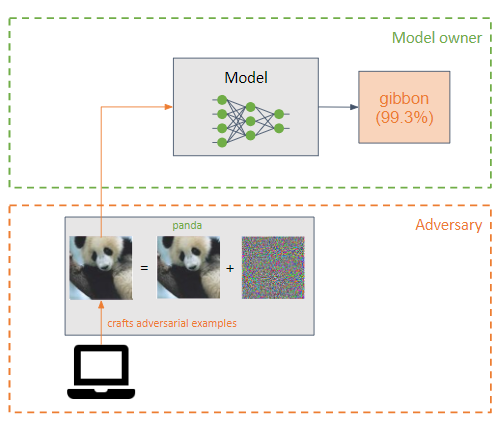
They are similar to poisoning attacks, but their main difference is that evasion attacks try to exploit the weaknesses of the model in the inference phase.
The goal of the adversary is for adversarial examples to be imperceptible to a human.
Two types of attack can be performed depending on the output desired by the opponent:
-
Targeted: the adversary aims to obtain a prediction of his choice.
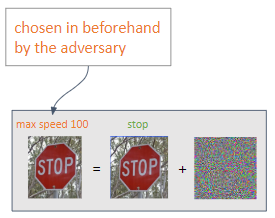
-
Untargeted: the adversary intends to achieve a misclassification.

The most common attacks are white-box attacks:
🛡️ Defensive actions 🛡️
-
Adversarial training, which consists of crafting adversarial examples during training to allow the model to learn features of the adversarial examples, making the model more robust to this type of attack.
-
Transformations on inputs.
-
Gradient masking/regularization. Not very effective.
-
Weak defenses.
-
Prompt Injection Defenses: Every practical and proposed defense against prompt injection.
-
Lakera PINT Benchmark: The Prompt Injection Test (PINT) Benchmark provides a neutral way to evaluate the performance of a prompt injection detection system, like Lakera Guard, without relying on known public datasets that these tools can use to optimize for evaluation performance.
-
Devil’s Inference: A method to adversarially assess the Phi-3 Instruct model by observing the attention distribution across its heads when exposed to specific inputs. This approach prompts the model to adopt the ‘devil’s mindset’, enabling it to generate outputs of a violent nature.
-
Over-the-Air Adversarial Attack Detection: from Datasets to Defenses
-
Harnessing Hyperbolic Geometry for Harmful Prompt Detection and Sanitization
🔗 Useful links 🔗
- Practical Black-Box Attacks against Machine Learning
- The Limitations of Deep Learning in Adversarial Settings
- Towards Evaluating the Robustness of Neural Networks
- Distillation as a Defense to Adversarial Perturbations Against Deep Neural Networks
- Adversarial examples in the physical world
- Ensemble Adversarial Training: Attacks and Defenses
- Towards Deep Learning Models Resistant to Adversarial Attacks
- Intriguing properties of neural networks
- Explaining and Harnessing Adversarial Examples
- Delving into Transferable Adversarial Examples and Black-box Attacks
- Adversarial machine learning at scale
- Black-box Adversarial Attacks with Limited Queries and Information
- Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks
- Decision-Based Adversarial Attacks: Reliable Attacks Against Black-Box Machine Learning Models
- Boosting Adversarial Attacks with Momentum
- The Space of Transferable Adversarial Examples
- Countering Adversarial Images using Input Transformations
- Defense-GAN: Protecting Classifiers Against Adversarial Attacks Using Generative Models
- Synthesizing Robust Adversarial Examples
- Mitigating adversarial effects through randomization
- On Detecting Adversarial Perturbations
- Adversarial Patch
- PixelDefend: Leveraging Generative Models to Understand and Defend against Adversarial Examples
- One Pixel Attack for Fooling Deep Neural Networks
- Efficient Defenses Against Adversarial Attacks
- Robust Physical-World Attacks on Deep Learning Visual Classification
- Adversarial Perturbations Against Deep Neural Networks for Malware Classification
- 3D Adversarial Attacks Beyond Point Cloud
- Adversarial Perturbations Fool Deepfake Detectors
- Adversarial Deepfakes: Evaluating Vulnerability of Deepfake Detectors to Adversarial Examples
- An Overview of Vulnerabilities of Voice Controlled Systems
- FastWordBug: A Fast Method To Generate Adversarial Text Against NLP Applications
- Phantom of the ADAS: Securing Advanced Driver Assistance Systems from Split-Second Phantom Attacks
- llm-attacks: Universal and Transferable Attacks on Aligned Language Models.
- Attacks on AI Models: Prompt Injection vs supply chain poisoning
- Prompt Injection attack against LLM-integrated Applications
- garak: LLM vulnerability scanner.
- promptfoo: Open-source LLM red teaming with 100+ attack types. AI Red teaming, pentesting, and vulnerability scanning for LLMs.
- Simple Adversarial Transformations in PyTorch
- ChatGPT Plugins: Data Exfiltration via Images & Cross Plugin Request Forgery
- Image Hijacks: Adversarial Images can Control Generative Models at Runtime
- Multi-attacks: Many images + the same adversarial attack → many target labels
- ACTIVE: Towards Highly Transferable 3D Physical Camouflage for Universal and Robust Vehicle Evasion
- LLM Red Teaming GPTS’s: Prompt Leaking, API Leaking, Documents Leaking
- Human-Producible Adversarial Examples
- Multilingual Jailbreak Challenges in Large Language Models
- Misusing Tools in Large Language Models With Visual Adversarial Examples
- AutoDAN: Interpretable Gradient-Based Adversarial Attacks on Large Language Models
- Multimodal Injection: (Ab)using Images and Sounds for Indirect Instruction Injection in Multi-Modal LLMs.
- JailbreakingLLMs: Jailbreaking Black Box Large Language Models in Twenty Queries.
- Tree of Attacks: Jailbreaking Black-Box LLMs Automatically
- GPTs: Leaked prompts of GPTs.
- AI Exploits: A collection of real world AI/ML exploits for responsibly disclosed vulnerabilities.
- LLM Agents can Autonomously Hack Websites
- Cloudflare announces Firewall for AI
- PromptInject: Framework that assembles prompts in a modular fashion to provide a quantitative analysis of the robustness of LLMs to adversarial prompt attacks.
- LLM Red Teaming: Adversarial, Programming, and Linguistic approaches VS ChatGPT, Claude, Mistral, Grok, LLAMA, and Gemini
- The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
- Prompt Injection / JailBreaking a Banking LLM Agent (GPT-4, Langchain)
- GitHub Copilot Chat: From Prompt Injection to Data Exfiltration
- Adversarial Examples are Misaligned in Diffusion Model Manifolds
- Image-to-Text Logic Jailbreak: Your Imagination Can Help You Do Anything
- Mitigating Skeleton Key, a new type of generative AI jailbreak technique
- Image Obfuscation Benchmark: This repository contains the code to evaluate models on the image obfuscation benchmark, first presented in Benchmarking Robustness to Adversarial Image Obfuscations.
- Jailbreaking Large Language Models with Symbolic Mathematics
- Adversarial Reasoning at Jailbreaking Time
- How we estimate the risk from prompt injection attacks on AI systems
- Adversarial Misuse of Generative AI
- Defeating Prompt Injections by Design
- Mitigating prompt injection attacks with a layered defense strategy
- Logic layer Prompt Control Injection (LPCI): A Novel Security Vulnerability Class in Agentic Systems
- Prompt injection engineering for attackers: Exploiting GitHub Copilot
- The State of Adversarial Prompts
- TransferBench: Benchmarking Ensemble-based Black-box Transfer Attacks
- Attention Tracker: Detecting Prompt Injection Attacks in LLMs
- The Attacker Moves Second: Stronger Adaptive Attacks Bypass Defenses Against Llm Jailbreaks and Prompt Injections
- Weaponizing Calendar Invites: A Semantic Attack on Google Gemini
- GTIG AI Threat Tracker: Distillation, Experimentation, and (Continued) Integration of AI for Adversarial Use
- How Cline Was Compromised: Prompt Injection and Dangling Commits in the Cline Supply Chain Attack
- Aguara: Security scanner for AI agent skills & MCP servers
- Robust AI Security and Alignment: A Sisyphean Endeavor?
- SkillSpector: Security scanner for AI agent skills. Detect vulnerabilities, malicious patterns, and security risks..
🛠️ Tools 🛠️
| Name | Type | Supported algorithms | Supported attack types | Attack/Defence | Supported frameworks | Popularity |
|---|---|---|---|---|---|---|
| Cleverhans | Image | Deep Learning | Evasion | Attack | Tensorflow, Keras, JAX | |
| Foolbox | Image | Deep Learning | Evasion | Attack | Tensorflow, PyTorch, JAX | |
| ART | Any type (image, tabular data, audio,…) | Deep Learning, SVM, LR, etc. | Any (extraction, inference, poisoning, evasion) | Both | Tensorflow, Keras, Pytorch, Scikit Learn | |
| TextAttack | Text | Deep Learning | Evasion | Attack | Keras, HuggingFace | |
| Advertorch | Image | Deep Learning | Evasion | Both | — | |
| AdvBox | Image | Deep Learning | Evasion | Both | PyTorch, Tensorflow, MxNet | |
| DeepRobust | Image, graph | Deep Learning | Evasion | Both | PyTorch | |
| Counterfit | Any | Any | Evasion | Attack | — | |
| Adversarial Audio Examples | Audio | DeepSpeech | Evasion | Attack | — |
ART
Adversarial Robustness Toolbox, abbreviated as ART, is an open-source Adversarial Machine Learning library for testing the robustness of machine learning models.

It is developed in Python and implements extraction, inversion, poisoning and evasion attacks and defenses.
ART supports the most popular frameworks: Tensorflow, Keras, PyTorch, MxNet, and ScikitLearn among many others.
It is not limited to the use of models that use images as input but also supports other types of data, such as audio, video, tabular data, etc.
Cleverhans
Cleverhans is a library for performing evasion attacks and testing the robustness of a deep learning model on image models.

It is developed in Python and integrates with the Tensorflow, Torch and JAX frameworks.
It implements numerous attacks such as L-BFGS, FGSM, JSMA, C&W, among others.
🔧 Use 🔧
AI is used to accomplish malicious tasks and boost classic attacks.
🕵️♂️ Pentesting 🕵️♂️
- Continuous CyberBattleSim: A simulation tool for training and evaluating scalable and generalizable reinforcement learning agents for critical attack path discovery in networks.
- GyoiThon: Next generation penetration test tool, intelligence gathering tool for web server.
- Cochise: LLM-agent performing autonomous penetration test against Microsoft Windows Active Directory (using GOAD as testbed).
- HackingBuddyGPT: LLMs x PenTesting.
- Deep Exploit: Fully automatic penetration test tool using Deep Reinforcement Learning.
- AutoPentest-DRL: Automated penetration testing using deep reinforcement learning.
- DeepGenerator: Fully automatically generate injection codes for web application assessment using Genetic Algorithm and Generative Adversarial Networks.
- Eyeballer: Eyeballer is meant for large-scope network penetration tests where you need to find “interesting” targets from a huge set of web-based hosts.
- Nebula: AI-Powered Ethical Hacking Assistant.
- AI-OPS: Penetration Testing AI Assistant based on open source LLMs.
- Can LLMs Hack Enterprise Networks?: Autonomous Assumed Breach Penetration-Testing Active Directory Networks
- Teams of LLM Agents can Exploit Zero-Day Vulnerabilities
- Insights and Current Gaps in Open-Source LLM Vulnerability Scanners: A Comparative Analysis
- Comparing AI Agents to Cybersecurity Professionals in Real-World Penetration Testing
- CAI: An Open, Bug Bounty-Ready Cybersecurity AI
- Shannon: Shannon Lite is an autonomous, white-box AI pentester for web applications and APIs. It analyzes your source code, identifies attack vectors, and executes real exploits to prove vulnerabilities before they reach production.
- OpenHack: AI-powered multi-agent scanner that finds SQLi, XSS, IDOR, and auth bypass in source code, then verifies each finding through sandbox execution and browser replay. On par with Claude Opus 4.6 at roughly 40x lower cost.
- offsec-ai: Python library and CLI that combines classic network reconnaissance with modern AI/LLM security testing.
🦠 Malware 🦠
- DeepLocker: Concealing targeted attacks with AI locksmithing, by IBM Labs on BH.
- An Overview of Artificial Intelligence Used in Malware: A curated list of AI Malware resources.
- DeepObfusCode: Source code obfuscation through sequence-to-sequence networks.
- AutoCAT: Reinforcement learning for automated exploration of cache-timing attacks.
- AI-BASED BOTNET: A game-theoretic approach for AI-based botnet attack defence.
- SECML_Malware: Python library for creating adversarial attacks against Windows Malware detectors.
- Transcendent-release: Using conformal evaluation to detect concept drift affecting malware detection.
🗺️ OSINT 🗺️
- SNAP_R: Generate automatically spear-phishing posts on social media.
- SpyScrap: SpyScrap combines facial recognition methods to filter the results and uses natural language processing to obtain important entities from the website the user appears.
- Darkforensic-7b. It is a 5-7B-Instruct model trained on a curated corpus of real dark web findings (Tor + I2P, 3,290 sites covering 11 categories: marketplace, fraud, hacking, forum, leak, cyberattack, services, etc.) with synthetic Q&A pairs generated by Anthropic Claude Sonnet 4.6 and filtered for quality, relevance, and defensive intent.
📧 Phishing 📧
- DeepDGA: Implementation of DeepDGA: Adversarially-Tuned Domain Generation and Detection.
- ScamAgents: How AI Agents Can Simulate Human-Level Scam Calls
🕵 Threat Intelligence 🕵
- From Sands to Mansions: Enabling Automatic Full-Life-Cycle Cyberattack Construction with LLM
- CVE-LMTune: A unified framework for fine-tuning, evaluation, and live inference of language models for automated vulnerability classification based on MITRE taxonomies.
⚙️ Reverse engineering ⚙️
- We hid backdoors in ~40MB binaries and asked AI + Ghidra to find them
- Malware Reverse Engineering is no longer a human problem!
- GhidraMCP: MCP Server for Ghidra.
- ghidra-mcp: Production-grade Ghidra MCP Server — 179 MCP tools, 147 GUI + 172 headless endpoints, Ghidra Server integration, cross-binary documentation transfer, batch operations, AI documentation workflows, and Docker deployment for AI-powered reverse engineering.
🌀 Side channels 🌀
- SCAAML: Side Channel Attacks Assisted with Machine Learning.
👨🎤 Generative AI 👨🎤
🔊 Audio 🔊
🛠️ Tools 🛠️
- deep-voice-conversion: Deep neural networks for voice conversion (voice style transfer) in Tensorflow.
- tacotron: A TensorFlow implementation of Google’s Tacotron speech synthesis with pre-trained model (unofficial).
- Real-Time-Voice-Cloning: Clone a voice in 5 seconds to generate arbitrary speech in real-time.
- mimic2: Text to Speech engine based on the Tacotron architecture, initially implemented by Keith Ito.
- Neural-Voice-Cloning-with-Few-Samples: Implementation of Neural Voice Cloning with Few Samples Research Paper by Baidu.
- Vall-E: An unofficial PyTorch implementation of the audio LM VALL-E.
- voice-changer: Realtime Voice Changer.
- Retrieval-based-Voice-Conversion-WebUI: An easy-to-use Voice Conversion framework based on VITS.
- Audiocraft: Audiocraft is a library for audio processing and generation with deep learning. It features the state-of-the-art EnCodec audio compressor/tokenizer, along with MusicGen, a simple and controllable music generation LM with textual and melodic conditioning.
- VALL-E-X: An open source implementation of Microsoft’s VALL-E X zero-shot TTS model.
- OpenVoice: Instant voice cloning by MyShell.
- MeloTTS: High-quality multi-lingual text-to-speech library by MyShell.ai. Support English, Spanish, French, Chinese, Japanese and Korean.
- VoiceCraft: Zero-Shot Speech Editing and Text-to-Speech in the Wild.
- Parler-TTS: Inference and training library for high-quality TTS models.
- ChatTTS: A generative speech model for daily dialogue.
💡 Applications 💡
- Lip2Wav: Generate high quality speech from only lip movements.
- AudioLDM: Text-to-Audio Generation with Latent Diffusion Models
- deepvoice3_pytorch: PyTorch implementation of convolutional neural networks-based text-to-speech synthesis models.
- 🎸 Riffusion: Stable diffusion for real-time music generation.
- whisper.cpp: Port of OpenAI’s Whisper model in C/C++.
- TTS: 🐸💬 - a deep learning toolkit for Text-to-Speech, battle-tested in research and production.
- YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone.
- TorToiSe: A multi-voice TTS system trained with an emphasis on quality.
- DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism (SVS & TTS).
- WaveNet vocoder: Implementation of the WaveNet vocoder, which can generate high-quality raw speech samples conditioned on linguistic or acoustic features.
- Deepvoice3_pytorch: PyTorch implementation of convolutional neural networks-based text-to-speech synthesis models.
- eSpeak NG Text-to-Speech: eSpeak NG is an open source speech synthesizer that supports more than hundred languages and accents.
- RealChar: Create, Customize and Talk to your AI Character/Companion in Realtime (All in One Codebase!). Have a natural seamless conversation with AI everywhere (mobile, web and terminal) using LLM OpenAI GPT3.5/4, Anthropic Claude2, Chroma Vector DB, Whisper Speech2Text, ElevenLabs Text2Speech.
- Neural Voice Cloning with a Few Samples
- NAUTILUS: A Versatile Voice Cloning System
- Learning to Speak Fluently in a Foreign Language: Multilingual Speech Synthesis and Cross-Language Voice Cloning
- When Good Becomes Evil: Keystroke Inference with Smartwatch
- KeyListener: Inferring Keystrokes on QWERTY Keyboard of Touch Screen through Acoustic Signals
- This Voice Does Not Exist: On Voice Synthesis, Audio Deepfakes and Their Detection
- AudioSep: Separate Anything You Describe.
- stable-audio-tools: Generative models for conditional audio generation.
- GPT-SoVITS-WebUI: 1 min voice data can also be used to train a good TTS model! (few shot voice cloning).
- Hybrid-Net: Real-time audio source separation, generate lyrics, chords, beat.
- CosyVoice: Multi-lingual large voice generation model, providing inference, training and deployment full-stack ability.
- EasyVolcap: Accelerating Neural Volumetric Video Research.
🔎 Detection 🔎
- fake-voice-detection: Using temporal convolution to detect Audio Deepfakes.
- A robust voice spoofing detection system using novel CLS-LBP features and LSTM
- Voice spoofing detector: A unified anti-spoofing framework
- Securing Voice-Driven Interfaces Against Fake (Cloned) Audio Attacks
- DeepSonar: Towards Effective and Robust Detection of AI-Synthesized Fake Voices
- Fighting AI with AI: Fake Speech Detection Using Deep Learning
- A Review of Modern Audio Deepfake Detection Methods: Challenges and Future Directions
📷 Image 📷
🛠️ Tools 🛠️
- StyleGAN: StyleGAN - Official TensorFlow Implementation.
- StyleGAN2: StyleGAN2 - Official TensorFlow Implementation.
- stylegan2-ada-pytorch: StyleGAN2-ADA - Official PyTorch implementation.
- StyleGAN-nada: CLIP-Guided Domain Adaptation of Image Generators.
- StyleGAN3: Official PyTorch implementation of StyleGAN3.
- Imaginaire: Imaginaire is a pytorch library that contains the optimized implementation of several image and video synthesis methods developed at NVIDIA.
- ffhq-dataset: Flickr-Faces-HQ Dataset (FFHQ).
- DALLE2-pytorch: Implementation of DALL-E 2, OpenAI’s updated text-to-image synthesis neural network, in Pytorch.
- ImaginAIry: AI imagined images. Pythonic generation of stable diffusion images.
- Lama Cleaner: Image inpainting tool powered by SOTA AI Model. Remove any unwanted object, defect, or people from your pictures or erase and replace(powered by stable diffusion) anything on your pictures.
- Invertible-Image-Rescaling: This is the PyTorch implementation of paper: Invertible Image Rescaling.
- DifFace: Blind Face Restoration with Diffused Error Contraction (PyTorch).
- CodeFormer: Towards Robust Blind Face Restoration with Codebook Lookup Transformer.
- Custom Diffusion: Multi-Concept Customization of Text-to-Image Diffusion.
- Diffusers: 🤗 Diffusers: State-of-the-art diffusion models for image and audio generation in PyTorch.
- Stable Diffusion: High-Resolution Image Synthesis with Latent Diffusion Models.
- InvokeAI: InvokeAI is a leading creative engine for Stable Diffusion models, empowering professionals, artists, and enthusiasts to generate and create visual media using the latest AI-driven technologies. The solution offers an industry-leading WebUI, supports terminal use through a CLI, and serves as the foundation for multiple commercial products.
- Stable Diffusion web UI: Stable Diffusion web UI.
- Stable Diffusion Infinity: Outpainting with Stable Diffusion on an infinite canvas.
- Fast Stable Diffusion: fast-stable-diffusion + DreamBooth.
- GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images.
- Awesome AI Art Image Synthesis: A list of awesome tools, ideas, prompt engineering tools, collabs, models, and helpers for the prompt designer playing with aiArt and image synthesis. Covers Dalle2, MidJourney, StableDiffusion, and open source tools.
- Stable Diffusion: A latent text-to-image diffusion model.
- Weather Diffusion: Code for “Restoring Vision in Adverse Weather Conditions with Patch-Based Denoising Diffusion Models”.
- DF-GAN: A Simple and Effective Baseline for Text-to-Image Synthesis.
- Dall-E Playground: A playground to generate images from any text prompt using Stable Diffusion (past: using DALL-E Mini).
- MM-CelebA-HQ-Dataset: A large-scale face image dataset that allows text-to-image generation, text-guided image manipulation, sketch-to-image generation, GANs for face generation and editing, image caption, and VQA.
- Deep Daze: Simple command line tool for text-to-image generation using OpenAI’s CLIP and Siren (Implicit neural representation network).
- StyleMapGAN: Exploiting Spatial Dimensions of Latent in GAN for Real-time Image Editing.
- Kandinsky-2: Multilingual text2image latent diffusion model.
- DragGAN: Interactive Point-based Manipulation on the Generative Image Manifold.
- Segment Anything: The repository provides code for running inference with the SegmentAnything Model (SAM), links for downloading the trained model checkpoints, and example notebooks that show how to use the model.
- Segment Anything 2: The repository provides code for running inference with the Meta Segment Anything Model 2 (SAM 2), links for downloading the trained model checkpoints, and example notebooks that show how to use the model.
- MobileSAM: This is the official code for the MobileSAM project that makes SAM lightweight for mobile applications and beyond!
- FastSAM: Fast Segment Anything
- Infinigen: Infinite Photorealistic Worlds using Procedural Generation.
- DALL·E 3
- StreamDiffusion: A Pipeline-Level Solution for Real-Time Interactive Generation.
- AnyDoor: Zero-shot Object-level Image Customization.
- DiT: Scalable Diffusion Models with Transformers.
- BrushNet: A Plug-and-Play Image Inpainting Model with Decomposed Dual-Branch Diffusion.
- OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on.
- VAR: Official impl. of “Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction”.
- Imagine Flash: Accelerating Emu Diffusion Models with Backward Distillation
💡 Applications 💡
- ArtLine: A Deep Learning based project for creating line art portraits.
- Depix: Recovers passwords from pixelized screenshots.
- Bringing Old Photos Back to Life: Old Photo Restoration (Official PyTorch Implementation).
- Rewriting: Interactive tool to directly edit the rules of a GAN to synthesize scenes with objects added, removed, or altered. Change StyleGANv2 to make extravagant eyebrows, or horses wearing hats.
- Fawkes: Privacy preserving tool against facial recognition systems.
- Pulse: Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models.
- HiDT: Official repository for the paper “High-Resolution Daytime Translation Without Domain Labels”.
- 3D Photo Inpainting: 3D Photography using Context-aware Layered Depth Inpainting.
- SteganoGAN: SteganoGAN is a tool for creating steganographic images using adversarial training.
- Stylegan-T: Unlocking the Power of GANs for Fast Large-Scale Text-to-Image Synthesis.
- MegaPortraits: One-shot Megapixel Neural Head Avatars.
- eg3d: Efficient Geometry-aware 3D Generative Adversarial Networks.
- TediGAN: Pytorch implementation for TediGAN: Text-Guided Diverse Face Image Generation and Manipulation.
- DALLE-pytorch: Implementation / replication of DALL-E, OpenAI’s Text to Image Transformer, in Pytorch.
- StyleNeRF: This is the open source implementation of the ICLR2022 paper “StyleNeRF: A Style-based 3D-Aware Generator for High-resolution Image Synthesis”.
- DeepSVG: Official code for the paper “DeepSVG: A Hierarchical Generative Network for Vector Graphics Animation”. Includes a PyTorch library for deep learning with SVG data.
- NUWA: A unified 3D Transformer Pipeline for visual synthesis.
- Image-Super-Resolution-via-Iterative-Refinement: Unofficial implementation of Image Super-Resolution via Iterative Refinement by Pytorch.
- Lama: 🦙 LaMa Image Inpainting, Resolution-robust Large Mask Inpainting with Fourier Convolutions.
- Person_reID_baseline_pytorch: Pytorch ReID: A tiny, friendly, strong pytorch implement of object re-identification baseline.
- instruct-pix2pix: PyTorch implementation of InstructPix2Pix, an instruction-based image editing model.
- GFPGAN: GFPGAN aims at developing Practical Algorithms for Real-world Face Restoration.
- DeepVecFont: Synthesizing High-quality Vector Fonts via Dual-modality Learning.
- Stargan v2 Tensorflow: Official Tensorflow Implementation.
- StyleGAN2 Distillation: Paired image-to-image translation, trained on synthetic data generated by StyleGAN2 outperforms existing approaches in image manipulation.
- Extracting Training Data from Diffusion Models
- Mann-E - Mann-E (Persian: مانی) is an art generator model based on the weights of Stable Diffusion 1.5 and data gathered from artistic material available on Pinterest
- End-to-end Trained CNN Encode-Decoder Networks for Image Steganography
- Grounded-Segment-Anything: Marrying Grounding DINO with Segment Anything & Stable Diffusion & Tag2Text & BLIP & Whisper & ChatBot - Automatically Detect , Segment and Generate Anything with Image, Text, and Audio Inputs.
- AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning.
- BasicSR: Open Source Image and Video Restoration Toolbox for Super-resolution, Denoise, Deblurring, etc. Currently, it includes EDSR, RCAN, SRResNet, SRGAN, ESRGAN, EDVR, BasicVSR, SwinIR, ECBSR, etc. Also support StyleGAN2 and DFDNet.
- Real-ESRGAN: Real-ESRGAN aims at developing Practical Algorithms for General Image/Video Restoration.
- ESRGAN: Enhanced SRGAN. Champion PIRM Challenge on Perceptual Super-Resolution.
- MixNMatch: Multifactor Disentanglement and Encoding for Conditional Image Generation.
- Clarity-upscaler: Reimagined image upscaling for everyone.
- One-step Diffusion with Distribution Matching Distillation
- Invisible Stitch: Generating Smooth 3D Scenes with Depth Inpainting.
- SSR: Single-view 3D Scene Reconstruction with High-fidelity Shape and Texture.
- InvSR: Arbitrary-steps Image Super-resolution via Diffusion Inversion.
- REPARO: Compositional 3D Assets Generation with Differentiable 3D Layout Alignment.
- Gen3DSR: Generalizable 3D Scene Reconstruction via Divide and Conquer from a Single View.
- ml-sharp: Sharp Monocular View Synthesis in Less Than a Second.
🔎 Detection 🔎
- stylegan3-detector: StyleGAN3 Synthetic Image Detection.
- stylegan2-projecting-images: Projecting images to latent space with StyleGAN2.
- FALdetector: Detecting Photoshopped Faces by Scripting Photoshop.
- B-Free: A Bias-Free Training Paradigm for More
General AI-generated Image Detection.
- Detection of Images Generated by Multi-Modal Models
🎥 Video 🎥
🛠️ Tools 🛠️
- DeepFaceLab: DeepFaceLab is the leading software for creating deepfakes.
- faceswap: Deepfakes Software For All.
- dot: The Deepfake Offensive Toolkit.
- SimSwap: An arbitrary face-swapping framework on images and videos with one single trained model!
- faceswap-GAN: A denoising autoencoder + adversarial losses and attention mechanisms for face swapping.
- Celeb DeepFakeForensics: A Large-scale Challenging Dataset for DeepFake Forensics.
- VGen: A holistic video generation ecosystem for video generation building on diffusion models.
- MuseV: Infinite-length and High Fidelity Virtual Human Video Generation with Visual Conditioned Parallel Denoising.
- GLEE: General Object Foundation Model for Images and Videos at Scale.
- T-Rex: Towards Generic Object Detection via Text-Visual Prompt Synergy.
- DynamiCrafter: Animating Open-domain Images with Video Diffusion Priors.
- Mora: More like Sora for Generalist Video Generation.
💡 Applications 💡
- face2face-demo: pix2pix demo that learns from facial landmarks and translates this into a face.
- Faceswap-Deepfake-Pytorch: Faceswap with Pytorch or DeepFake with Pytorch.
- Point-E: Point cloud diffusion for 3D model synthesis.
- EGVSR: Efficient & Generic Video Super-Resolution.
- STIT: Stitch it in Time: GAN-Based Facial Editing of Real Videos.
- BackgroundMattingV2: Real-Time High-Resolution Background Matting.
- MODNet: A Trimap-Free Portrait Matting Solution in Real Time.
- Background-Matting: Background Matting: The World is Your Green Screen.
- First Order Model: This repository contains the source code for the paper First Order Motion Model for Image Animation.
- Articulated Animation: This repository contains the source code for the CVPR’2021 paper Motion Representations for Articulated Animation.
- Real Time Person Removal: Removing people from complex backgrounds in real time using TensorFlow.js in the web browser.
- AdaIN-style: Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization.
- Frame Interpolation: Frame Interpolation for Large Motion.
- Awesome-Image-Colorization: 📚 A collection of Deep Learning based Image Colorization and Video Colorization papers.
- SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation.
- roop: One-click deepfake (face swap).
- StableVideo: Text-driven Consistency-aware Diffusion Video Editing.
- MagicEdit: High-Fidelity Temporally Coherent Video Editing.
- Rerender_A_Video: Zero-Shot Text-Guided Video-to-Video Translation.
- DreamEditor: Text-Driven 3D Scene Editing with Neural Fields.
- 4K4D: Real-Time 4D View Synthesis at 4K Resolution.
- AnimateAnyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation.
- Moore-AnimateAnyone: This repository reproduces AnimateAnyone.
- audio2photoreal: From Audio to Photoreal Embodiment: Synthesizing Humans in Conversations.
- MagicVideo-V2: Multi-Stage High-Aesthetic Video Generation
- LWM: A general-purpose large-context multimodal autoregressive model. It is trained on a large dataset of diverse long videos and books using RingAttention and can perform language, image, and video understanding and generation.
- AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation.
- Champ: Controllable and Consistent Human Image Animation with 3D Parametric Guidance.
- Streamv2v: Streaming Video-to-Video Translation with Feature Banks.
- Deep-Live-Cam: Real time face swap and one-click video deepfake with only a single image.
- Sapiens: Foundation for Human Vision Models.
- ViVid-1-to-3: Novel View Synthesis with Video Diffusion Models.
- VGGT: Visual Geometry Grounded Transformer.
- LayerPano3D: Layered 3D Panorama for Hyper-Immersive Scene Generation.
- RealmDreamer: Text-Driven 3D Scene Generation with Inpainting and Depth Diffusion.
🔎 Detection 🔎
- FaceForensics++: FaceForensics dataset.
- DeepFake-Detection: Towards deepfake detection that actually works.
- fakeVideoForensics: Detect deep fakes videos.
- Deepfake-Detection: The Pytorch implemention of Deepfake Detection based on Faceforensics++.
- SeqDeepFake: PyTorch code for SeqDeepFake: Detecting and Recovering Sequential DeepFake Manipulation.
- PCL-I2G: Unofficial Implementation: Learning Self-Consistency for Deepfake Detection.
- DFDC DeepFake Challenge: A prize winning solution for DFDC challenge.
- POI-Forensics: Audio-Visual Person-of-Interest DeepFake Detection.
- Standardizing Detection of Deepfakes: Why Experts Say It’s Important
- Want to spot a deepfake? Look for the stars in their eyes
- Fit for Purpose? Deepfake Detection in the Real World
📄 Text 📄
🛠️ Tools 🛠️
- GLM-130B: An Open Bilingual Pre-Trained Model.
- LongtermChatExternalSources: GPT-3 chatbot with long-term memory and external sources.
- sketch: AI code-writing assistant that understands data content.
- LangChain: ⚡ Building applications with LLMs through composability ⚡.
- ChatGPT Wrapper: API for interacting with ChatGPT using Python and from Shell.
- openai-python: The OpenAI Python library provides convenient access to the OpenAI API from applications written in the Python language.
- Beto: Spanish version of the BERT model.
- GPT-Code-Clippy: GPT-Code-Clippy (GPT-CC) is an open source version of GitHub Copilot, a language model – based on GPT-3, called GPT-Codex.
- GPT Neo: An implementation of model parallel GPT-2 and GPT-3-style models using the mesh-tensorflow library.
- ctrl: Conditional Transformer Language Model for Controllable Generation.
- Llama: Inference code for LLaMA models.
- Llama2
- Llama Guard 3
- UL2 20B: An Open Source Unified Language Learner
- burgpt: A Burp Suite extension that integrates OpenAI’s GPT to perform an additional passive scan for discovering highly bespoke vulnerabilities, and enables running traffic-based analysis of any type.
- Ollama: Get up and running with Llama 2 and other large language models locally.
- SneakyPrompt: Jailbreaking Text-to-image Generative Models.
- Copilot-For-Security: A generative AI-powered security solution that helps increase the efficiency and capabilities of defenders to improve security outcomes at machine speed and scale, while remaining compliant with responsible AI principles.
- Copilot-For-Security: A generative AI-powered security solution that helps increase the efficiency and capabilities of defenders to improve security outcomes at machine speed and scale, while remaining compliant with responsible AI principles.
- LM Studio: Discover, download, and run local LLMs
- Bypass GPT: Convert AI Text to Human-like Content
- MGM: The framework supports a series of dense and MoE Large Language Models (LLMs) from 2B to 34B with image understanding, reasoning, and generation simultaneously.
- Secret Llama: Fully private LLM chatbot that runs entirely with a browser with no server needed. Supports Mistral and LLama 3.
- Llama3: The official Meta Llama 3 GitHub site.
- Unsloth: Finetune Llama 3.3, Mistral, Phi-4, Qwen 2.5 & Gemma 2x faster with 80% less memory!
🔎 Detection 🔎
- Detecting Fake Text: Giant Language Model Test Room.
- Grover: Code for Defending Against Neural Fake News.
- Rebuff.ai: Prompt Injection Detector.
- New AI classifier for indicating AI-written text
- Discover the 4 Magical Methods to Detect AI-Generated Text (including ChatGPT)
- GPTZero
- AI Content Detector (beta)
- GPTHuman AI Humanizer.
- A Watermark for Large Language Models
- Can AI-Generated Text be Reliably Detected?
- GPT detectors are biased against non-native English writers
- To ChatGPT, or not to ChatGPT: That is the question!
- Can linguists distinguish between ChatGPT/AI and human writing?: A study of research ethics and academic publishing
- ChatGPT is bullshit
💡 Applications 💡
- handwrite: Handwrite generates a custom font based on your handwriting sample.
- GPT Sandbox: The goal of this project is to enable users to create cool web demos using the newly released OpenAI GPT-3 API with just a few lines of Python.
- PassGAN: A Deep Learning Approach for Password Guessing.
- GPT Index: GPT Index is a project consisting of a set of data structures designed to make it easier to use large external knowledge bases with LLMs.
- nanoGPT: The simplest, fastest repository for training/finetuning medium-sized GPTs.
- whatsapp-gpt
- ChatGPT Chrome Extension: A ChatGPT Chrome extension. Integrates ChatGPT into every text box on the internet.
- Unilm: Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities.
- minGPT: A minimal PyTorch re-implementation of the OpenAI GPT (Generative Pretrained Transformer) training.
- CodeGeeX: An Open Multilingual Code Generation Model.
- OpenAI Cookbook: Examples and guides for using the OpenAI API.
- 🧠 Awesome ChatGPT Prompts: This repo includes ChatGPT prompt curation to use ChatGPT better.
- Alice: Giving ChatGPT access to a real terminal.
- Security Code Review With ChatGPT
- Do Users Write More Insecure Code with AI Assistants?
- Bypassing Gmail’s spam filters with ChatGPT
- Recurrent GANs Password Cracker For IoT Password Security Enhancement
- PentestGPT: A GPT-empowered penetration testing tool.
- GPT Researcher: GPT based autonomous agent that does online comprehensive research on any given topic.
- GPT Engineer: Specify what you want it to build, the AI asks for clarification, and then builds it.
- localpilot: Use GitHub Copilot locally on your Macbook with one-click!
- WormGPT: New AI Tool Allows Cybercriminals to Launch Sophisticated Cyber Attacks
- PoisonGPT: How we hid a lobotomized LLM on Hugging Face to spread fake news
- PassGPT: Password Modeling and (Guided) Generation with Large Language Models
- DeepPass — Finding Passwords With Deep Learning
- GPTFuzz: Red Teaming Large Language Models with Auto-Generated Jailbreak Prompts.
- Open Interpreter: OpenAI’s Code Interpreter in your terminal, running locally.
- Eureka: Human-Level Reward Design via Coding Large Language Models.
- MetaCLIP: Demystifying CLIP Data.
- LLM OSINT: Proof-of-concept method of using LLMs to gather information from the internet and then perform a task with this information.
- HackingBuddyGPT: LLMs x PenTesting.
- ChatGPT-Jailbreaks: Official jailbreak for ChatGPT (GPT-3.5). Send a long message at the start of the conversation with ChatGPT to get offensive, unethical, aggressive, human-like answers in English and Italian.
- Magika: Detect file content types with deep learning.
- Jan: An open source alternative to ChatGPT that runs 100% offline on your computer.
- LibreChat: Enhanced ChatGPT Clone: Features OpenAI, Assistants API, Azure, Groq, GPT-4 Vision, Mistral, Bing, Anthropic, OpenRouter, Vertex AI, Gemini, AI model switching, message search, langchain, DALL-E-3, ChatGPT Plugins, OpenAI Functions, Secure Multi-User System, Presets, completely open-source for self-hosting.
- Lumina-T2X: A unified framework for Text to Any Modality Generation.
📚 Misc 📚
- Awesome GPT + Security: A curated list of awesome security tools, experimental case or other interesting things with LLM or GPT.
- 🚀 Awesome Reinforcement Learning for Cyber Security: A curated list of resources dedicated to reinforcement learning applied to cyber security.
- Awesome Machine Learning for Cyber Security: A curated list of amazingly awesome tools and resources related to the use of machine learning for cyber security.
- Hugging Face Diffusion Models Course: Materials for the Hugging Face Diffusion Models Course.
- Awesome-AI-Security: A curated list of AI security resources.
- ML for Hackers: Code accompanying the book “Machine Learning for Hackers”.
- Awful AI: Awful AI is a curated list to track current scary usages of AI - hoping to raise awareness.
- NIST AI Risk Management Framework Playbook
- SoK: Explainable Machine Learning for Computer Security Applications
- Who Evaluates the Evaluators? On Automatic Metrics for Assessing AI-based Offensive Code Generators
- Vulnerability Prioritization: An Offensive Security Approach
- MITRE ATLAS™ (Adversarial Threat Landscape for Artificial-Intelligence Systems)
- A Survey on Reinforcement Learning Security with Application to Autonomous Driving
- How to avoid machine learning pitfalls: a guide for academic researchers
- A curated list of AI Security & Privacy events
- NIST AI 100-2 E2025: Adversarial Machine Learning. A Taxonomy and Terminology of Attacks and Mitigations.
- 🇪🇸 RootedCon 2023 - Inteligencia artificial ofensiva - ¿Cómo podemos estar preparados?
- Security of AI-Systems: Fundamentals - Adversarial Deep Learning
- Beyond the Safeguards: Exploring the Security Risks of ChatGPT
- The AI Attack Surface Map v1.0
- On the Impossible Safety of Large AI Models
- Frontier AI Regulation: Managing Emerging Risks to Public Safety
- Multilayer Framework for Good Cybersecurity Practices for AI
- Introducing Google’s Secure AI Framework
- OWASP Top 10 for LLM
- Awesome LLM Security: A curation of awesome tools, documents and projects about LLM Security.
- A framework to securely use LLMs in companies. Part 1: Overview of Risks. Part 2: Managing risk. Part 3: Securing ChatGPT and GitHub Copilot.
- A Study on Robustness and Reliability of Large Language Model Code Generation
- Identifying AI-generated images with SynthID
- Auditing Large Language Models: A Three-Layered Approach
- Resolving the battle of short‑ vs. long‑term AI risk
- FraudGPT: The Villain Avatar of ChatGPT
- AI Risks - Schneier on Security
- Use of LLMs for Illicit Purposes: Threats, Prevention Measures, and Vulnerabilities
- AI Red-Teaming Is Not a One-Stop Solution to AI Harms: Recommendations for Using Red-Teaming for AI Accountability
- A Taxonomy of Trustworthiness for Artificial Intelligence
- Managing AI Risks in an Era of Rapid Progress
- Google - Acting on our commitment to safe and secure AI
- Offensive ML Playbook
- Demystifying Generative AI 🤖 A Security Researcher’s Notes
- GenAI-Security-Adventures: An open-source initiative to share notes, presentations, and a diverse collection of experiments presented in Jupyter Notebooks, all aimed at helping you grasp the essential concepts behind large language models and exploring the intriguing intersection of security and natural language processing.
- AI Safety Camp connects you with a research lead to collaborate on a project – to see where your work could help ensure future AI is safe.
- Guidelines for secure AI system development
- Approach to Artificial Intelligence and Cybersecurity. BEST PRACTICE REPORT
- Stanford Safe, Secure, and Trustworthy AI EO 14110 Tracker
- Awesome ML Security: A curated list of awesome machine learning security references, guidance, tools, and more.
- AI’s Predictable Path: 7 Things to Expect From AI in 2024+
- Artificial Intelligence and Cybersecurity (in Spanish :es:)
- Vigil: Detect prompt injections, jailbreaks, and other potentially risky Large Language Model (LLM) inputs.
- Generative AI Models - Opportunities and Risks for Industry and Authorities
- Deploying AI Systems Securely. Best Practices for Deploying Secure and Resilient AI Systems
- NIST AI 600-1: Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile
- :fr: ANSSI: Recommandations De Sécurité Pour Un Système d’IA Générative (Security Recommendations for a Generative AI System)
- PyRIT: The Python Risk Identification Tool for generative AI (PyRIT) is an open-access automation framework to empower security professionals and machine learning engineers to proactively find risks in their generative AI systems.
- OWASP-Agentic-AI: Working to create the OWASP Top 10 for Agentic AI (AI Agent Security).
- Towards Guaranteed Safe AI: A Framework for Ensuring Robust and Reliable AI Systems
- Defining Real AI Risks
- Secure approach to generative AI
- Large Language Models in Cybersecurity
- Hey, That’s My Model! Introducing Chain & Hash, An LLM Fingerprinting Technique
- Generative AI Misuse: A Taxonomy of Tactics and Insights from Real-World Data
- AI Risk Repository
- Revisiting AI Red-Teaming
- German-French recommendations for the use of AI programming assistants
- Scalable watermarking for identifying large language model outputs
- Lessons from red teaming 100 generative AI products
- LLM red teaming guide
- Open Challenges in Multi-Agent Security: Towards Secure Systems of Interacting AI Agents
- LLMs unlock new paths to monetizing exploits
- Spill The Beans: Exploiting CPU Cache Side-Channels to Leak Tokens from Large Language Models
- Enhanced automated code vulnerability repair using large language models
- Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task
- AIRTBench: Measuring Autonomous AI Red Teaming Capabilities in Language Models
- Slopsquatting
- SP 800-53 Control Overlays for Securing AI Systems Concept Paper
- Agents Rule of Two: A Practical Approach to AI Agent Security
- ETSI EN 304 223 V2.1.1 (2025-12): Securing Artificial Intelligence (SAI); Baseline Cyber Security Requirements for AI Models and Systems
- Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?
- Handbook of Digital Face Manipulation and Detection
- Security Considerations for Artificial Intelligence Agents
- Position: AI Security Policy Should Target Systems, Not Models
- The “AI Vulnerability Storm”: Building a “Mythos-ready” Security Program
- 🇪🇸 Guía de buenas prácticas frente al modelo de IA ofensiva
📊 Surveys 📊
- The Threat of Offensive AI to Organizations
- Artificial Intelligence in the Cyber Domain: Offense and Defense
- A survey on adversarial attacks and defenses
- Adversarial Deep Learning: A Survey on Adversarial Attacks and Defense Mechanisms on Image Classification
- A Survey of Privacy Attacks in Machine Learning
- Towards Security Threats of Deep Learning Systems: A Survey
- A Survey on Security Threats and Defensive Techniques of Machine Learning: A Data-Driven View
- SoK: Security and Privacy in Machine Learning
- Adversarial Machine Learning: The Rise in AI-Enabled Crime and its Role in Spam Filter Evasion
- Threats, Vulnerabilities, and Controls of Machine Learning Based Systems: A Survey and Taxonomy
- Adversarial Attacks and Defences: A Survey
- Security Matters: A Survey on Adversarial Machine Learning
- A Survey on Adversarial Attacks for Malware Analysis
- Adversarial Machine Learning in Image Classification: A Survey Towards the Defender’s Perspective
- A Survey of Robust Adversarial Training in Pattern Recognition: Fundamental, Theory, and Methodologies
- Privacy in Large Language Models: Attacks, Defenses and Future Directions
🗣 Maintainers 🗣
 Miguel Hernández |
 José Ignacio Escribano |
©️ License ©️
![]()